live demo
To insert some data and make some queries, open another terminal window and start
irb, the Ruby shell:
irb
In the
irb prompt, require the Ruby client library:
require 'rubygems'
require 'cassandra'
include SimpleUUID
Now instantiate a client object:
twitter = Cassandra.new('Twitter')
Let’s insert a few things:
user = {'screen_name' => 'buttonscat'}
twitter.insert(:Users, '5', user)
tweet1 = {'text' => 'Nom nom nom nom nom.', 'user_id' => '5'}
twitter.insert(:Statuses, '1', tweet1)
tweet2 = {'text' => '@evan Zzzz....', 'user_id' => '5', 'reply_to_id' => '8'}
twitter.insert(:Statuses, '2', tweet2)
Notice that the two status records do not have all the same columns. Let’s go ahead and connect them to our user record:
twitter.insert(:UserRelationships, '5', {'user_timeline' => {UUID.new => '1'}})
twitter.insert(:UserRelationships, '5', {'user_timeline' => {UUID.new => '2'}})
The
UUID.new call creates a collation key based on the current time; our tweet ids are stored in the values.
Now we can query our user’s tweets:
timeline = twitter.get(:UserRelationships, '5', 'user_timeline', :reversed => true)
timeline.map { |time, id| twitter.get(:Statuses, id, 'text') }
# => ["@evan Zzzz....", "Nom nom nom nom nom."]
Two tweet bodies, returned in recency order—not bad at all. In a
similar fashion, each time a user tweets, we could loop through their
followers and insert the status key into their follower’s
home_timeline relationship, for handling general status delivery.
the data model
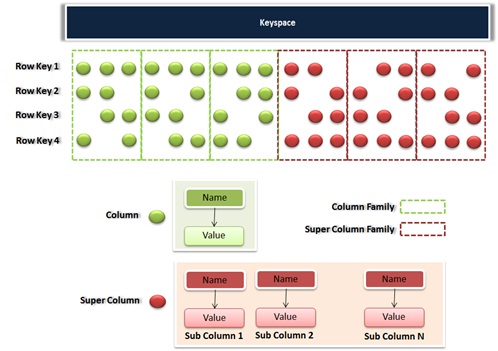
Cassandra is best thought of as a 4 or 5 dimensional hash. The usual way to refer to a piece of data is as follows: a
keyspace, a
column family, a
key, an
optional super column, and a
column. At the end of that chain lies a single, lonely value.
Let’s break down what these layers mean.
- Keyspace (also confusingly called “table”): the
outer-most level of organization. This is usually the name of the
application. For example,
'Twitter' and 'Wordpress' are both good keyspaces. Keyspaces must be defined at startup in the storage-conf.xml file.
- Column family: a slice of data corresponding to a
particular key. Each column family is stored in a separate file on disk,
so it can be useful to put frequently accessed data in one column
family, and rarely accessed data in another. Some good column family
names might be
:Posts, :Users and :UserAudits. Column families must be defined at startup.
- Key: the permanent name of the record. You can query over ranges of keys in a column family, like
:start => '10050', :finish => '10070'—this is the only index Cassandra provides for free. Keys are defined on the fly.
After the column family level, the organization can diverge—this is a feature unique to Cassandra. You can choose either:
- A column: this is a tuple with a name and a value. Good columns might be
'screen_name' => 'lisa4718' or 'Google' => 'http://google.com'.It
is common to not specify a particular column name when requesting a
key; the response will then be an ordered hash of all columns. For
example, querying for (:Users, '174927')might return:
{'name' => 'Lisa Jones',
'gender' => 'f',
'screen_name' => 'lisa4718'}
In this case, name, gender, and screen_name
are all column names. Columns are defined on the fly, and different
records can have different sets of column names, even in the same
keyspace and column family. This lets you use the column name itself as
either structure or data. Columns can be stored in recency order, or alphabetical by name, and all columns keep a timestamp.
- A super column: this is a named list. It contains
standard columns, stored in recency order.Say Lisa Jones has bookmarks
in several categories. Querying
(:UserBookmarks, '174927')might return:
{'work' => {
'Google' => 'http://google.com',
'IBM' => 'http://ibm.com'},
'todo': {...},
'cooking': {...}}
Here, work, todo, and cooking are all super column names. They are defined on the fly, and there can be any number of them per row. :UserBookmarks is the name of the super column family. Super columns are stored in alphabetical order, with their sub columns physically adjacent on the disk.
Super columns and standard columns cannot be mixed at the same (4th)
level of dimensionality. You must define at startup which column
families contain standard columns, and which contain super columns with
standard columns inside them.
Super columns are a great way to store one-to-many indexes to other
records: make the sub column names TimeUUIDs (or whatever you’d like to
use to sort the index), and have the values be the foreign key. We saw
an example of this strategy in the demo, above.
If this is confusing, don’t worry. We’ll now look at two example schemas in depth.
twitter schema
Here is the schema definition we used for the demo, above. It is based on Eric Florenzano’s
Twissandra, but updated for 0.7:
{"Twitter":{
"Users":{
"comparator_type":"org.apache.cassandra.db.marshal.UTF8Type",
"column_type":"Standard"},
"Statuses":{
"comparator_type":"org.apache.cassandra.db.marshal.UTF8Type",
"column_type":"Standard"},
"StatusRelationships":{
"subcomparator_type":"org.apache.cassandra.db.marshal.TimeUUIDType",
"comparator_type":"org.apache.cassandra.db.marshal.UTF8Type",
"column_type":"Super"},
}}
You can load a schema with this command (replace
schema.json with your own filename):
bin/cassandra-cli --host localhost --batch < schema.json
The server must be running; as of version 0.7, Cassandra supports updating the schema at runtime.
What could be in
StatusRelationships? Maybe a list of
users who favorited the tweet? Having a super column family for both
record types lets us index each direction of whatever many-to-many
relationships we come up with.
Here’s how the data is organized:
Cassandra lets you distribute the keys across the cluster either randomly, or in order, via the
Partitioner option in the
storage-conf.xml file.
For the Twitter application, if we were using the order-preserving
partitioner, all recent statuses would be stored on the same node. This
would cause hotspots. Instead, we should use the random partitioner.
Alternatively, we could preface the status keys with the user key, which has less temporal locality. If we used
user_id:status_id as the status key, we could do range queries on the user fragment to get tweets-by-user, avoiding the need for a
user_timeline super column.
multi-blog schema
Here’s a another schema, suggested to me by
Jonathan Ellis, the primary Cassandra maintainer. It’s for a multi-tenancy blog platform:
{"Multiblog":{
"Blogs":{
"comparator_type":"org.apache.cassandra.db.marshal.TimeUUIDType",
"column_type":"Standard"},
"Comments":{
"comparator_type":"org.apache.cassandra.db.marshal.TimeUUIDType",
"column_type":"Standard"}
},}
Imagine we have a blog named 'The Cutest Kittens'. We will insert a row when the first post is made as follows:
require 'rubygems'
require 'cassandra/0.7'
include SimpleUUID
multiblog = Cassandra.new('Multiblog')
multiblog.insert(:Blogs, 'The Cutest Kittens',
{ UUID.new =>
'{"title":"Say Hello to Buttons Cat","body":"Buttons is a cute cat."}' })
UUID.new generates a unique, sortable column name, and the JSON hash contains the post details. Let’s insert another:
multiblog.insert(:Blogs, 'The Cutest Kittens',
{ UUID.new =>
'{"title":"Introducing Commie Cat","body":"Commie is also a cute cat"}' })
Now we can find the latest post with the following query:
post = multiblog.get(:Blogs, 'The Cutest Kittens', :reversed => true).to_a.first
On our website, we can build links based on the readable representation of the UUID:
guid = post.first.to_guid
# => "b06e80b0-8c61-11de-8287-c1fa647fd821"
If the user clicks this string in a permalink, our app can find the post directly via:
multiblog.get(:Blogs, 'The Cutest Kittens', :start => UUID.new(guid), :count => 1)
For comments, we’ll use the post UUID as the outermost key:
multiblog.insert(:Comments, guid,
{UUID.new => 'I like this cat. - Evan'})
multiblog.insert(:Comments, guid,
{UUID.new => 'I am cuter. - Buttons'})
Now we can get all comments (oldest first) for a post by calling:
multiblog.get(:Comments, guid)
We could paginate them by passing
:start with a UUID. See
this presentation to learn more about token-based pagination.
We have sidestepped two problems with this data model: we don’t have
to maintain separate indexes for any lookups, and the posts and comments
are stored in separate files, where they don’t cause as much write
contention. Note that we didn’t need to use any super columns, either.
storage layout and api comparison
The storage strategy for Cassandra’s standard model is the same as BigTable’s. Here’s a comparison chart:
|
multi-file |
per-file |
intra-file |
| Relational |
server |
database |
table* |
primary key |
column value |
|
|
| BigTable |
cluster |
table |
column family |
key |
column name |
column value |
|
| Cassandra, standard model |
cluster |
keyspace |
column family |
key |
column name |
column value |
|
* With fixed column names.
Column families are stored in
column-major order,
which is why people call BigTable a column-oriented database. This is
not the same as a column-oriented OLAP database like Sybase IQ—it
depends on whether your data model considers keys to span column
families or not.
In row-orientation, the column names are the
structure, and you think of the column families as
containing keys. This is the convention in relational databases.
In column-orientation, the column names are the
data, and the column families are the structure. You think of the key as
containing the column family,
which is the convention in BigTable. (In Cassandra, super columns are
also stored in column-major order—all the sub columns are together.)
In Cassandra’s Ruby API, parameters are expressed in storage order, for clarity:
| Relational |
SELECT `column` FROM `database`.`table` WHERE `id` = key; |
| BigTable |
table.get(key, "column_family:column") |
| Cassandra: standard model |
keyspace.get("column_family", key, "column") |
Note that Cassandra’s internal Thrift interface mimics BigTable in some ways, but this is being changed.